
You’ve got a small student model you want to make smarter. Somewhere out there, a bigger, wiser teacher model has all the answers. Standard knowledge distillation says: have the student match the teacher’s output distribution, position by position, via KL divergence. Elegant. Clean. Works great.
Until the teacher and student use different tokenizers. Then the whole thing falls apart.

The Tokenizer Lock-In Problem
Standard per-token KL divergence works by aligning the teacher’s and student’s next-token probability distributions at every position. That only makes sense if both models produce distributions over the same vocabulary. So if you’ve committed to a Llama-3.2-1B student (Llama tokenizer), you can only distill from other Llama-family teachers. The much stronger Qwen3-4B? Incompatible tokenizer. Phi-4-mini? Also incompatible. A combination of both? You don’t even get to ask the question.
Cross-tokenizer KD: knowledge distillation between a teacher and student that use different tokenizers (and thus incompatible output vocabularies), requiring explicit alignment before any loss can be computed.
This is a real, practical constraint. Model families increasingly diverge in their tokenization choices. A digit-splitting tokenizer (like Qwen3) breaks "201" into ["2", "0", "1"], while a number-packing tokenizer (like Llama-3) keeps it as a single token "201". Neither is wrong; they’re just different dialects, and mixing them in standard KD produces gibberish gradients.
The NVIDIA team’s new paper, X-Token, fixes this with a surprisingly clean solution: a sparse projection matrix that bridges vocabularies, plus two complementary loss formulations that handle the two distinct ways cross-tokenizer distillation can fail.
The Existing Escape Hatches, and Where They Snap
Two methods already tried to solve this before X-Token.
ULD (Universal Logit Distillation) takes the nuclear option: don’t bother aligning token identities at all. Sort both the teacher’s and student’s distributions by probability rank, then minimize the $\ell_1$ distance between the sorted sequences. The 5th most likely teacher token “teaches” the 5th most likely student token, regardless of what they actually are. It works, but it throws away all token-identity information.
GOLD is the current state of the art and is substantially smarter. It first does span alignment: both token sequences are grouped into text-consistent “chunks” (spans that decode to the same text substring), so positions at least correspond to the same text. Then it applies a hybrid loss: tokens that match exactly by string in both vocabularies go into a common set $\mathcal{C}$ and get direct KL supervision; everything else goes into an uncommon remainder and gets ULD-style rank matching.
\[\mathcal{L}_{GOLD} = \mathcal{L}_{common} + \mathcal{L}_{ULD}\]Sounds reasonable. And it is, until you hit a specific kind of tokenizer mismatch. Here’s the horror story.
Qwen3 splits multi-digit numbers into individual digits: "201" → ["2", "0", "1"]. Llama-3 treats "201" as one token. So under Qwen supervision, all 1,100 of Llama’s 2- and 3-digit numerals fail the string-equality check and get dumped into the uncommon bucket. Every last one.
The result? Training Llama-3.2-1B on GSM8k math problems with Qwen3-4B as teacher, using GOLD, achieves an accuracy of 2.56. The same student trained with standard same-tokenizer KD from the much weaker Llama-3.2-3B teacher gets 12.89. GOLD with a stronger teacher is worse than no cross-tokenizer distillation at all. Somehow a method designed to help is actively destroying math ability.
Why the Partition Is Actively Harmful
GOLD’s partition hurts uncommon tokens through two distinct mechanisms.
Erroneous gradients from rank-based matching. When a numeral like "201" lands in the uncommon set, ULD pairs it with the teacher token at the same probability rank. That might be a special character, a punctuation mark, or basically anything. The gradient that flows back into the student for "201" is telling it to look like whatever the teacher has at position 47 (or wherever the rank falls). This is identity-agnostic noise.
Suppressive gradients from the common-KL term. Here’s the subtler one. The common-KL loss looks like it only touches tokens in $\mathcal{C}$. But it uses full-vocabulary softmax internally, which means gradients flow back to all logits, including the uncommon ones. The math works out to:
\[\frac{\partial \mathcal{L}_{common}}{\partial z_u} = \hat{p}[u] \cdot c(u) \geq 0, \quad u \in \mathcal{U}\]where $c(u) = \sum_{v \in \mathcal{C}_T} \hat{q}[v] \in [0,1]$ is the total probability mass the teacher puts on the common set. The gradient is non-negative, which means gradient descent decreases $z_u$ every step. Every uncommon token’s probability mass is being quietly suppressed even though it never appears in the loss. The student is simultaneously getting noisy rank-based “supervision” and having its probability mass suppressed by the normalization. No wonder numerals get destroyed.
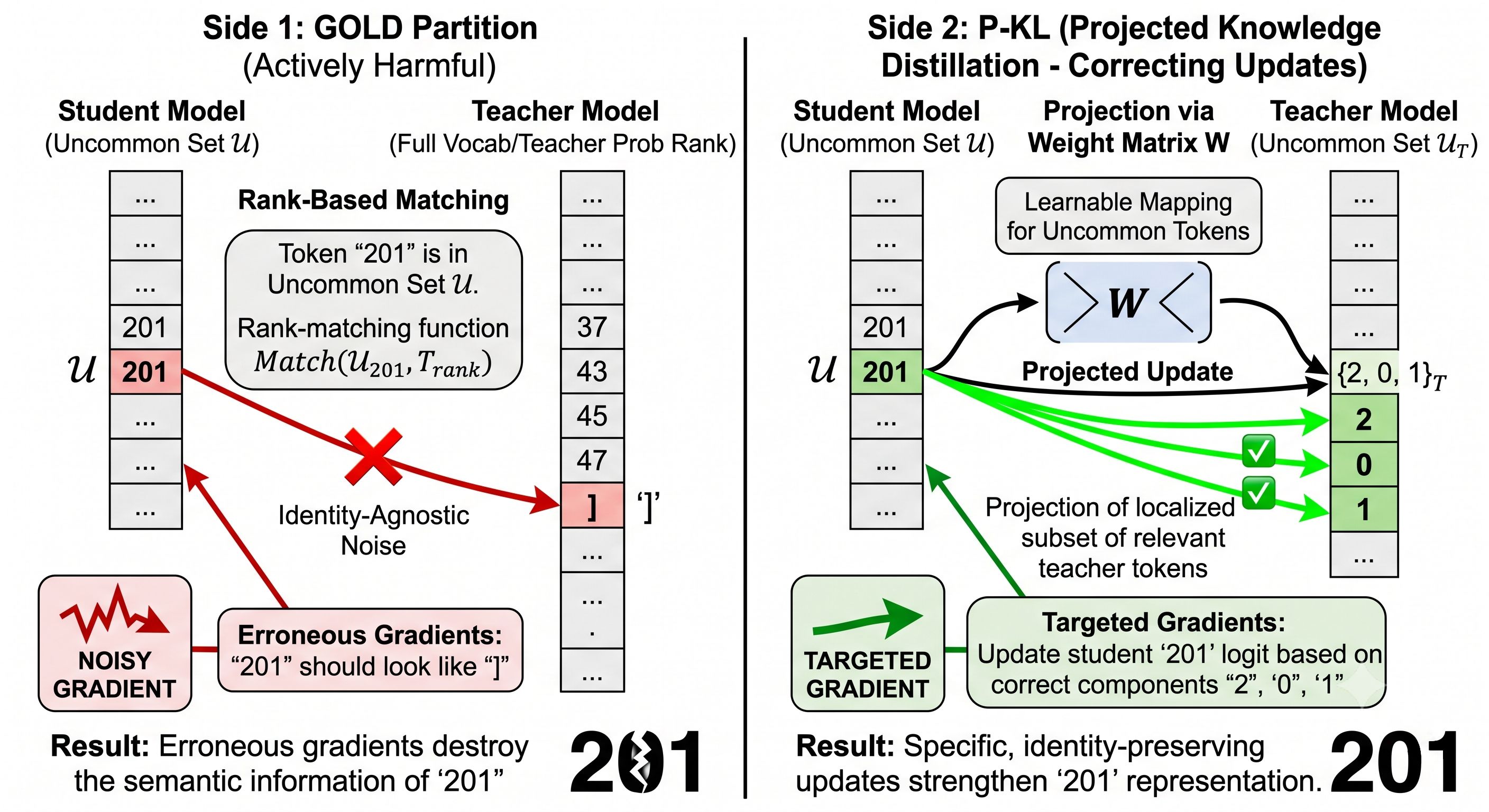
X-Token Fix #1: P-KL (Drop the Partition)
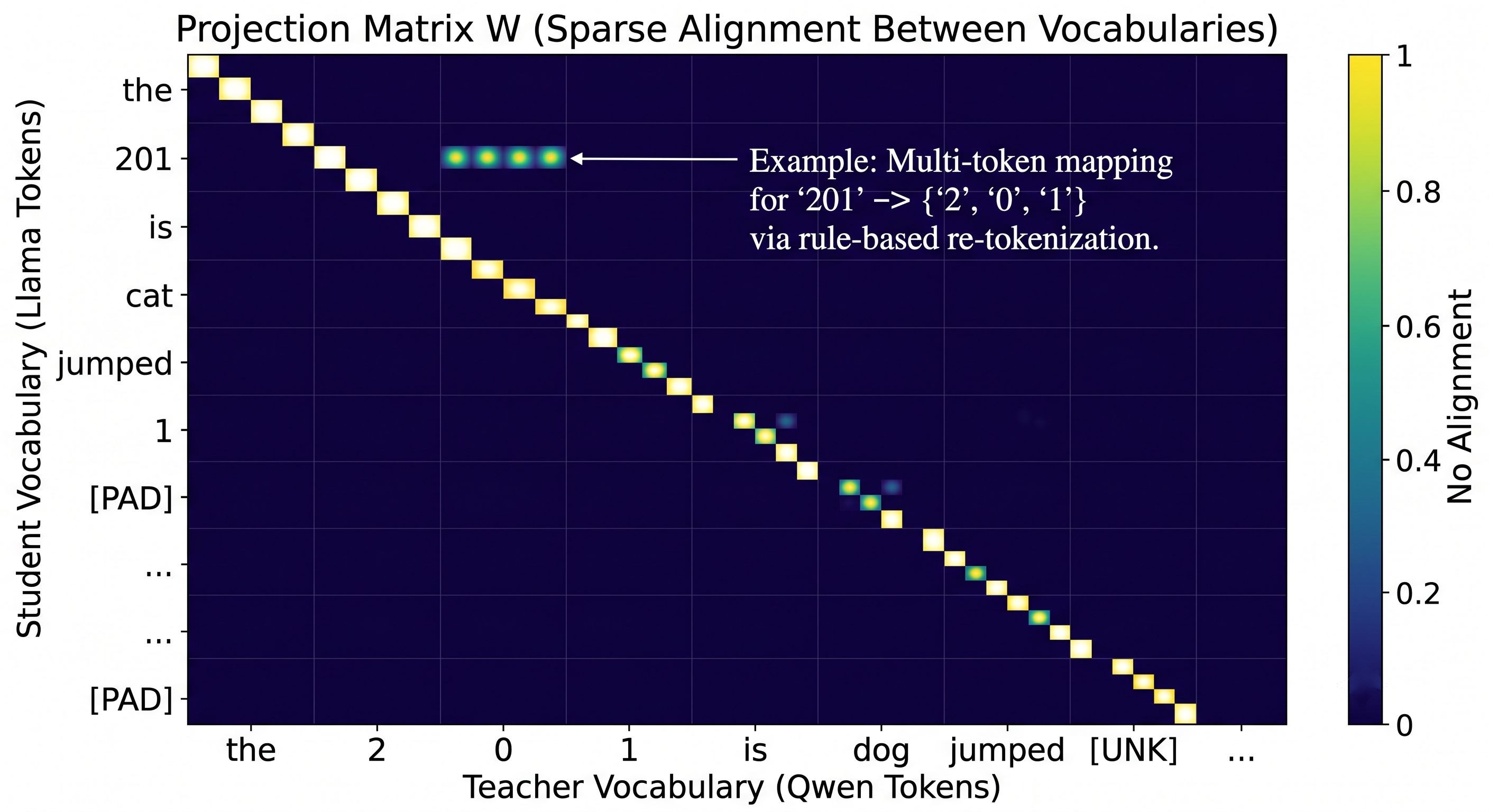
The core insight of P-KL is that you don’t need the partition at all if you have a principled way to bridge the two vocabularies directly. Enter the projection matrix $W \in \mathbb{R}^{\vert V_S \vert \times \vert V_T \vert}$, where $V_S$ is the student vocab and $V_T$ is the teacher vocab.
$W$ is built deterministically in two passes (no training needed):
- Exact-match pass: for each student token $u$ and teacher token $v$ whose decoded strings match after canonicalization (normalizing space prefixes, newline markers, byte-fallback tokens, etc.), set $W[u, v] = 1$.
- Multi-token rule pass: for any student token without an exact match (say,
"201"), re-tokenize its text under the teacher tokenizer to get["2", "0", "1"], then set $W[u, v_0] = \alpha$ and $W[u, v_k] = \beta^k$ with $(\alpha, \beta) = (0.9, 0.1)$. Concentrate weight on the leading sub-token.
Each row is truncated to its top-4 entries and row-normalized. The matrix is computed once, before training. It can optionally be jointly learned alongside the student during KD (Table 3 in the paper shows learned $W$ wins in 5 out of 6 benchmark columns, with a modest but consistent margin).
With $W$ in hand, P-KL projects the student’s chunk distribution into teacher vocabulary space and does a plain KL:
\[\tilde{q}[v] = \sum_{u \in V_S} W[u, v] \cdot \hat{p}[u], \qquad \mathcal{L}_{P\text{-}KL} = \mathrm{KL}\!\left(\hat{q} \,\|\, \tilde{q}\right)\]No partition. No uncommon bucket. No suppressive gradients. "201" gets its probability mass routed onto {2, 0, 1} in the teacher’s vocabulary via $W$, and the teacher’s response to those three tokens provides clean, identity-aware supervision.
The results are dramatic. GSM8k goes from 2.56 to 15.54 (a 6× jump). Overall average accuracy goes from 35.03 (GOLD) to 38.85 (+3.82 points). Crucially, this beats same-tokenizer KD from Llama-3.2-3B (which gets 12.89 on GSM8k), showing that cross-tokenizer KD with a stronger teacher can actually exceed the same-family ceiling when done right.
X-Token Fix #2: H-KL (Relax the Partition Instead of Dropping It)
P-KL is the right fix when the partition goes badly wrong. But what if it doesn’t? With Phi-4-mini as the teacher, all 1,100 of Llama’s 2- and 3-digit numerals stay safely in the common set (Phi-4-mini does not split digits). The partition is structurally fine.
In this regime, the partition is actually useful: exact-match pairs produce sharper, more targeted KL supervision than P-KL’s projected distribution, which blurs student probability mass across multiple teacher tokens via the multi-token rows of $W$. Dropping the partition here loses signal.
The fix isn’t to throw the partition away; it’s to make it less narrow. GOLD’s criterion for “common” is strict string equality. But $W$ exposes a richer set of near-equivalent pairs through teacher-side re-tokenization. H-KL keeps the hybrid loss structure, but extends the common set $\mathcal{C}$ by including each student token’s top-1 teacher match under $W$:
\[v^* = \arg\max_{v'} W[u, v'], \quad W[u, v^*] > 0\]This admits pairs like ("Hundreds", "Hund") that strict string equality would discard, since "Hundreds" re-tokenizes to ["Hund", "reds"] under the teacher, making "Hund" the natural top-1 match. These near-equivalent pairs now get direct KL supervision instead of noisy rank matching.
Result: +0.52 average accuracy over GOLD on the Phi-4-mini teacher. Not a 6× GSM8k moment, but a clean, consistent improvement from fixing the conservativeness of the matching criterion.
Choosing Between Them: A Coverage Audit
The choice between P-KL and H-KL comes down to one question: do critical tokens fall inside the common set or outside it? The paper proposes a simple coverage audit: group the student vocabulary by character class (digits by length, ASCII punctuation, alphabetic, etc.) and check the fraction that survives into $\mathcal{C}$.
| Llama category | Qwen3-4B common | Phi-4-mini common |
|---|---|---|
| 1-digit numerals | 13/13 (100%) | 13/13 (100%) |
| 2-digit numerals | 0/100 (0%) | 100/100 (100%) |
| 3-digit numerals | 0/1000 (0%) | 1000/1000 (100%) |
| ASCII punctuation | 88/88 (100%) | 88/88 (100%) |
The numbers tell the whole story. If critical tokens fall out (Qwen case): use P-KL. If the partition is sound (Phi case): use H-KL. The paper confirms this with a clean reversal in Table 2: P-KL outperforms H-KL by +3.55 avg on Qwen3-4B, while H-KL outperforms P-KL by +1.68 avg on Phi-4-mini. Apply each to the wrong teacher and you lose.
Multi-Teacher: Mixing a Math Brain and a Knowledge Brain
Both losses generalize naturally to multiple teachers. Each teacher gets its own projection matrix and its own loss (standard KL for same-tokenizer teachers, P-KL or H-KL for cross-tokenizer ones). The per-teacher losses are aggregated with static weights:
\[\mathcal{L}_{KD,multi} = \sum_{k=1}^{K} \lambda_k \cdot \frac{1}{\vert T^*_k \vert} \sum_{t \in T^*_k} \mathcal{L}_k^{(t)}\]The combined KD loss is then scaled against the cross-entropy term using a stop-gradient ratio:
\[\mathcal{L} = \underbrace{\mathrm{sg}\!\left(\frac{\mathcal{L}_{CE}}{\mathcal{L}_{KD}}\right)}_{\beta} \cdot \mathcal{L}_{KD} + \mathcal{L}_{CE}\]This keeps the two terms at consistent relative magnitude throughout training, without any tuned hyperparameters for the balance.
For teacher weighting, the paper tried entropy-based and confidence-based adaptive schemes. Simple static weights won. Good reminder that adaptive complexity isn’t free.
The interesting result is about complementarity. Combining Phi-4-mini (strong on math and reasoning) with Llama-3.2-3B (strong on commonsense, same tokenizer) yields 40.48 average accuracy, +1.3 over the best single-teacher result. But combining two reasoning-heavy cross-tokenizer teachers (Phi-mini + Qwen-4B) gives only 38.49, below the best single-teacher run. Overlapping capabilities interfere rather than combine. So “more teachers” only helps if you’re picking teachers with genuinely different strengths.
Results at a Glance
All numbers are on Llama-3.2-1B student, 3-shot evaluation.
| Setting | Method | MMLU | GSM8k | Avg |
|---|---|---|---|---|
| No distillation | Llama-1B base | 32.05 | 5.69 | 33.96 |
| No distillation | Continued pre-training | 40.50 | 10.25 | 36.63 |
| Same tokenizer | Llama-3B → 1B | 43.83 | 12.89 | 38.40 |
| Cross-tokenizer | Qwen-4B, GOLD | 42.56 | 2.56 | 35.03 |
| Cross-tokenizer | Qwen-4B, X-Token (P-KL) | 44.67 | 15.54 | 38.85 |
| Cross-tokenizer | Phi-mini, GOLD | 43.50 | 16.50 | 38.66 |
| Cross-tokenizer | Phi-mini, X-Token (H-KL) | 43.93 | 19.11 | 39.18 |
| Multi-teacher | Phi-mini + Llama-3B (X-Token) | 46.32 | 20.39 | 40.48 |
Closing Thoughts
What I find cleanest about X-Token is how much it achieves without touching the model. No auxiliary heads, no extra forward passes, no architectural changes. Just a sparse matrix built from tokenizer string rules (you can cache it before training and never think about it again), and two loss formulations that handle the two distinct ways the prior art breaks.
The projection matrix also has a nice theoretical property: since each row is non-negative and sums to 1, multiplying by $W^\top$ is a convex combination, so the projected distribution is always a valid probability distribution over the teacher vocabulary. No normalization tricks needed.
The bigger takeaway is that tokenizer choice no longer has to constrain which teachers you can learn from. If you want to distill a Llama student from a Qwen teacher, the fact that Qwen splits digits differently is now a solvable alignment problem, not a hard blocker. And if you want to pull from three teachers across three tokenizer families simultaneously, X-Token handles the routing.
The paper is honest about its scope: one student model (Llama-3.2-1B), continued pre-training only, cross-tokenizer pairs that still share mostly-overlapping vocabularies. Instruction-tuned settings, larger students, and truly low-overlap tokenizer pairs (SentencePiece vs. BPE vs. byte-level) are left for future work. But as a proof of concept that the core failure modes of partition-based cross-tokenizer KD are fixable with clean projections, it’s pretty convincing.
Full paper: X-Token: Projection-Guided Cross-Tokenizer Knowledge Distillation