

Picking what to watch is a genuinely mundane problem, the kind you solve three times a week and never get better at. You already know you loved Parasite. You just want something like it. And every tool that is supposed to help immediately asks “what genre do you like?” which is useless, because you just told it.
That is the kind of problem an LLM with a couple of API tools is almost embarrassingly well-suited to solve. Claude already knows what Parasite is. Give it a way to query TMDB for real metadata and it can ask you the questions that actually matter: are you open to subtitles, do you want another Bong Joon-ho film, is the slow-burn class commentary the draw or the kinetic ending. After a round or two, it queries TMDB with the right filters and hands back a ranked list.
The whole thing is one Jekyll page, one Cloudflare Pages Function, and a tool-use loop against the Anthropic API. No backend server, no database, no auth. The site already lives on Cloudflare Pages, so the Function deploys alongside it on every git push. The build-and-ship story is as small as the code.
The problem with generic recommendation UIs
The standard recommender pattern is a static form. Pick a genre, pick a decade, pick a runtime, hit submit. The UX exists because the underlying system is a SQL query against a movie table, and the form fields map one-to-one onto WHERE clauses. The form is honest about what the system actually is.
But that is a poor model for how people actually decide what to watch. The information you have when you sit down on the couch is “I loved this thing, find me another.” The system needs to ask you about the specific axes that matter for that specific reference. For The Matrix, the interesting axis is philosophy versus action. For Parasite, it is whether you are open to subtitles. For The Dark Knight, it is whether you want more Nolan or just more grounded comic book movies. A generic form cannot ask that, because the question depends on a model that already understands the reference.
LLMs with tool use are an obvious fit. Claude already knows what The Matrix is about. If you give it a way to query TMDB for ground-truth metadata (genre IDs, keywords, the exact cast), it can both ground its questions in real data and return recommendations that are filterable, not hallucinated.
What I put together
A single page on this site, served by Jekyll, talks to a Cloudflare Pages Function at /api/chat. The Function runs a streaming tool-use loop against Claude Sonnet 4.5 with three TMDB tools registered: search_movie, get_movie_details, and discover_movies. Conversation state lives entirely in the browser as a messages array. Every request from the page sends the full history.
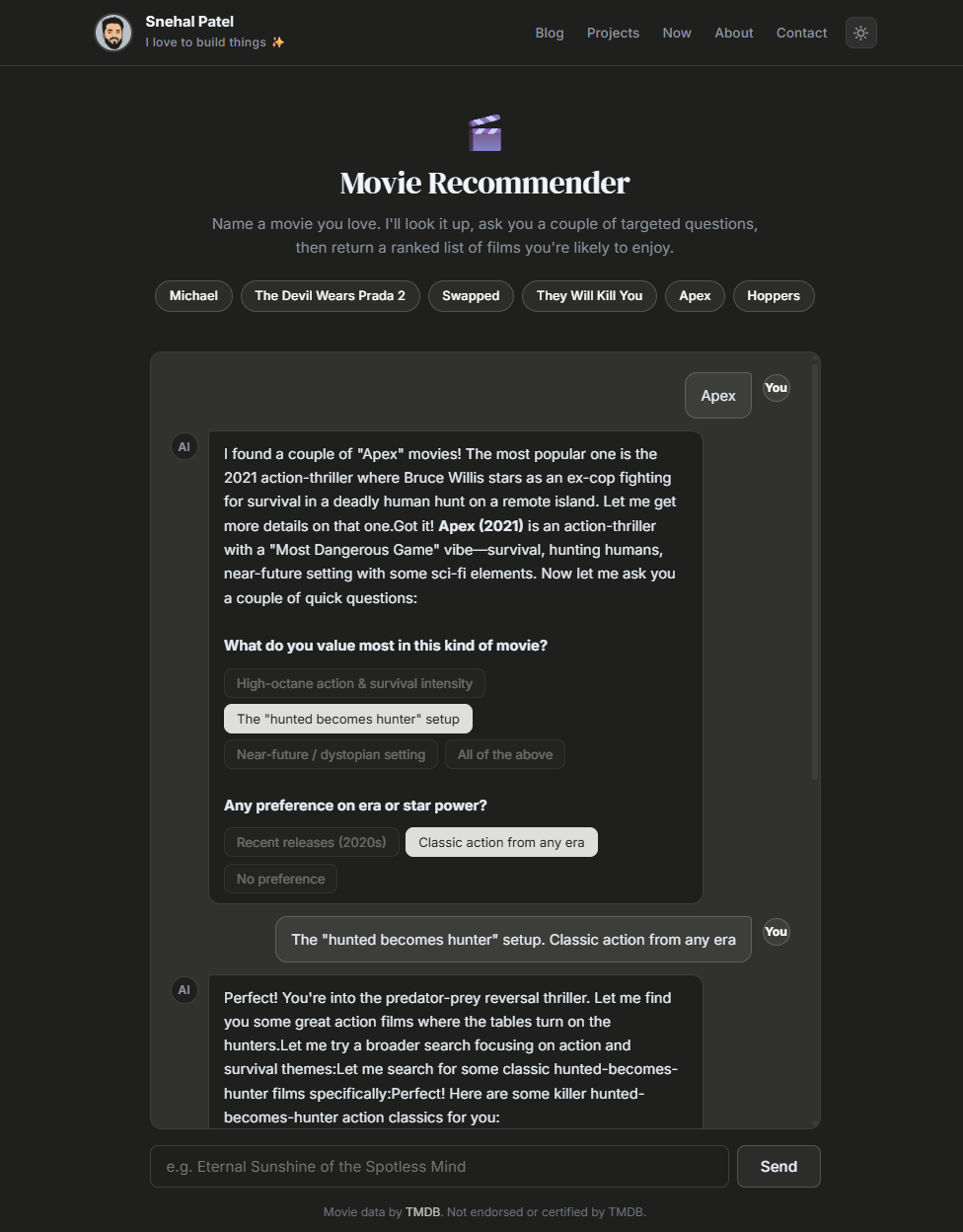
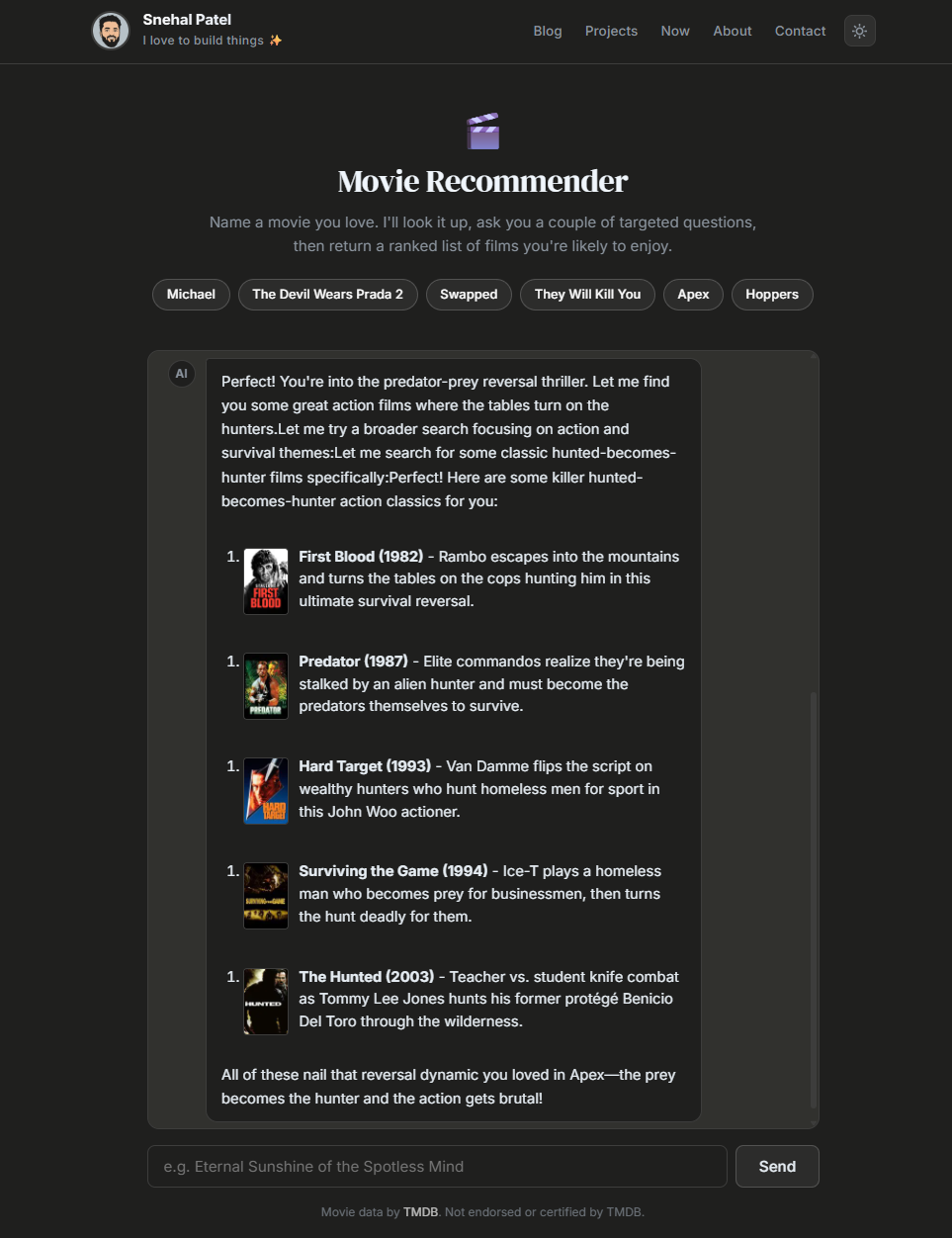
You type “Inception.” Claude calls search_movie, picks the right TMDB ID, calls get_movie_details to pull genres, keywords, and director, then asks you two or three questions tailored to what it just learned. Each question comes with pill-style answer options. You click one option per question group and when every group has a pick, all selected answers are joined and submitted together in a single message. Claude calls discover_movies with the appropriate filters and returns a ranked list, each item with a poster thumbnail pulled from TMDB’s image CDN. The whole thing usually completes in three or four iterations of the agent loop.
Stack: Jekyll (frontend), Cloudflare Pages Functions (backend), Anthropic Messages API with streaming tool use, TMDB API v3.
The relevant files are tiny: chat.js for the agent loop, plus a single Jekyll page with inline CSS and JS for the chat UI. No build step, no separate deployment, no wrangler invocation.
Under the Hood: A Stateless Agent on the Edge
The Function is roughly 200 lines of JavaScript. The response is a ReadableStream that stays open across all tool-use iterations, forwarding text deltas to the browser as server-sent events.
const stream = new ReadableStream({
async start(controller) {
const send = (obj) => controller.enqueue(encode(`data: ${JSON.stringify(obj)}\n\n`));
const working = [...messages];
for (let i = 0; i < MAX_ITERATIONS; i++) {
const body = await callClaudeStream(env.YOUR_LLM_KEY, working);
const { assistantContent, stopReason } = await processStream(
body,
delta => send({ type: "text", delta })
);
working.push({ role: "assistant", content: assistantContent });
if (stopReason !== "tool_use") { send({ type: "done" }); break; }
const toolResults = await executeTools(assistantContent, env.TMDB_API_KEY);
working.push({ role: "user", content: toolResults });
}
}
});
return new Response(stream, { headers: { "Content-Type": "text/event-stream" } });
Each iteration: open a streaming call to Claude, parse the SSE response chunk by chunk. Text deltas go straight to the browser as {type:"text",delta:"..."} events. Tool-use blocks are accumulated from input_json_delta fragments server-side, then executed against TMDB. The results get pushed back into the working message list and the loop continues, all on the same open response stream. A final {type:"done"} event closes the loop. Cap at eight iterations as a fuse against runaway loops.
The tool definitions are normal JSON schema. The most interesting one is discover_movies, which exposes a curated subset of TMDB’s /discover/movie filters: genre IDs, release date bounds, vote average, original language, keyword IDs, and a sort field. Claude composes these into a TMDB query based on whatever it has learned from the conversation. For a Parasite recommendation, it might call discover_movies with with_genres: "53,18" (Thriller plus Drama), with_original_language: "ko", and sort_by: "vote_average.desc".
{
name: "discover_movies",
description: "Find movies matching filters. Use this AFTER you have asked clarifying questions.",
input_schema: {
type: "object",
properties: {
with_genres: { type: "string" },
primary_release_date_gte: { type: "string" },
vote_average_gte: { type: "number" },
with_original_language: { type: "string" },
with_keywords: { type: "string" },
sort_by: { type: "string", enum: ["popularity.desc", "vote_average.desc", "primary_release_date.desc", "revenue.desc"] }
}
}
}
The TMDB client is three async functions. Each one trims the response down to just the fields the model actually needs (id, title, year, overview, genres, keywords, top cast, director, and poster_path). This matters: stuffing the entire raw TMDB response into a tool_result block burns tokens and slows the loop without making the recommendations any better. The system prompt tells Claude to format each recommendation with a markdown image tag pointing at TMDB’s image CDN (https://image.tmdb.org/t/p/w92{poster_path}), and a small extension to the markdown renderer turns those tags into <img> elements that float beside each list item.
The frontend is one HTML page with inline <style> and <script>. CSS variables from the site’s existing theme (--accent-2, --card-bg, --border) make it inherit dark mode for free. The JS reads the SSE stream from /api/chat, appends text deltas to a live bubble, and only finalizes the markdown (converting <ul> items to clickable pill buttons) once the done event arrives. State is one history array in memory. Refresh and the conversation resets.
Three design decisions worth calling out
Your tab, your problem
The Function is stateless. Every request includes the full conversation history; the Function does not remember anything between calls. This is the right default for a small public-facing demo for three reasons.
First, no database means no schema, no migrations, no rate limiting on writes, no PII concerns. Second, the conversation is short. A typical session is six or seven turns, which fits comfortably in the request body and in Claude’s context. Third, sending the full history on each request means the Worker can be horizontally scaled to infinity without any coordination, because each request is self-contained.
The cost is that a page refresh wipes the conversation. For this app that is fine. If someone wanted persistence later, the right move would be localStorage, not a server-side store.
Stop asking me what genre I like
The system prompt is the part of the project that took the most iteration. The first version said “ask the user clarifying questions.” The result was uniformly generic: “What genre do you like? Do you prefer recent films or classics?” Useless, and a regression from a static form, because at least a form does not pretend to be having a conversation.
The fix was negative examples in the prompt. The current version says: “ask 2-3 SPECIFIC clarifying questions. AVOID generic questions like what genre do you like, you already know the genre.” It also includes worked examples: for The Matrix, ask about philosophy versus action. For Parasite, ask about subtitle preference. With those examples in place, the model reliably grounds its questions in whatever get_movie_details returned, which is the whole point of having TMDB in the loop.
The lesson: when you give a model a tool, you also have to tell it how the tool’s output should change its behavior. Otherwise the tool data sits in the context unused.
One message per conversation turn, not one message per question
Claude asks two or three questions in a single response, each with a short list of answer options. The naive implementation converts those lists into pill buttons that each fire a form submit on click. That meant clicking the first pill immediately sent a half-formed response and triggered a new agent call before the user had answered anything else.
The fix: treat each <ul> in an assistant response as an independent question group with radio behavior. A click within a group selects that option and highlights it; it does not submit anything. Once every group in the bubble has a selection, the picks are joined into a single message and submitted automatically. One round trip, all context at once. The agent gets everything it needs to call discover_movies in the very next iteration rather than burning an extra exchange on each question.
The thing I keep coming back to is how small this is. Two files of real code (chat.js and the Jekyll page), a handful of TMDB endpoints, one Anthropic API call in a loop. The whole project fits in a single afternoon of focused work, including debugging the thing that always trips you up on TMDB (there are two API key formats and only one of them works with Bearer auth, ask me how I know). Streaming, poster thumbnails, and the multi-question pill UX each added maybe an hour on top of the working prototype.
What makes it feel like a real product rather than a toy demo is the agent loop plus the tool grounding. The model is not guessing at what Parasite is. It has the actual genres, the actual keywords, the actual director and cast. The recommendations come from a real filter query against TMDB, not from training data. The questions it asks are specific to what it learned. And the response streams in character by character while the tools run in the background, which turns out to matter more for perceived quality than any model tweak.
If you want to wire this pattern up against a different domain, the agent loop is generic and the tools are the interesting part. Book recommendations, podcast episodes, restaurant pairings: all the same shape with different APIs behind the tool definitions. Pick a mundane decision you make repeatedly. Find an API that has the data. Write three tool definitions. The agent loop is twenty lines.