If you have used Claude Code or Codex for more than a few sessions, you have probably noticed that first-turn pause. That brief hang before the agent does anything useful. I finally looked into why. Someone set up a proxy to count the tokens flowing between a coding agent and the API on each request. The number that came back was hard to believe. Before the agent had written a single line of code, before it had read a single file, it had already consumed 27,000 input tokens. On every single request.
The breakdown tells the story. System prompt: a few thousand tokens. Tool definitions: another several thousand. Memory files loaded at startup: more thousands. By the time the model saw the user’s actual task, over a quarter of a typical context budget was already spent on the agent talking to itself.
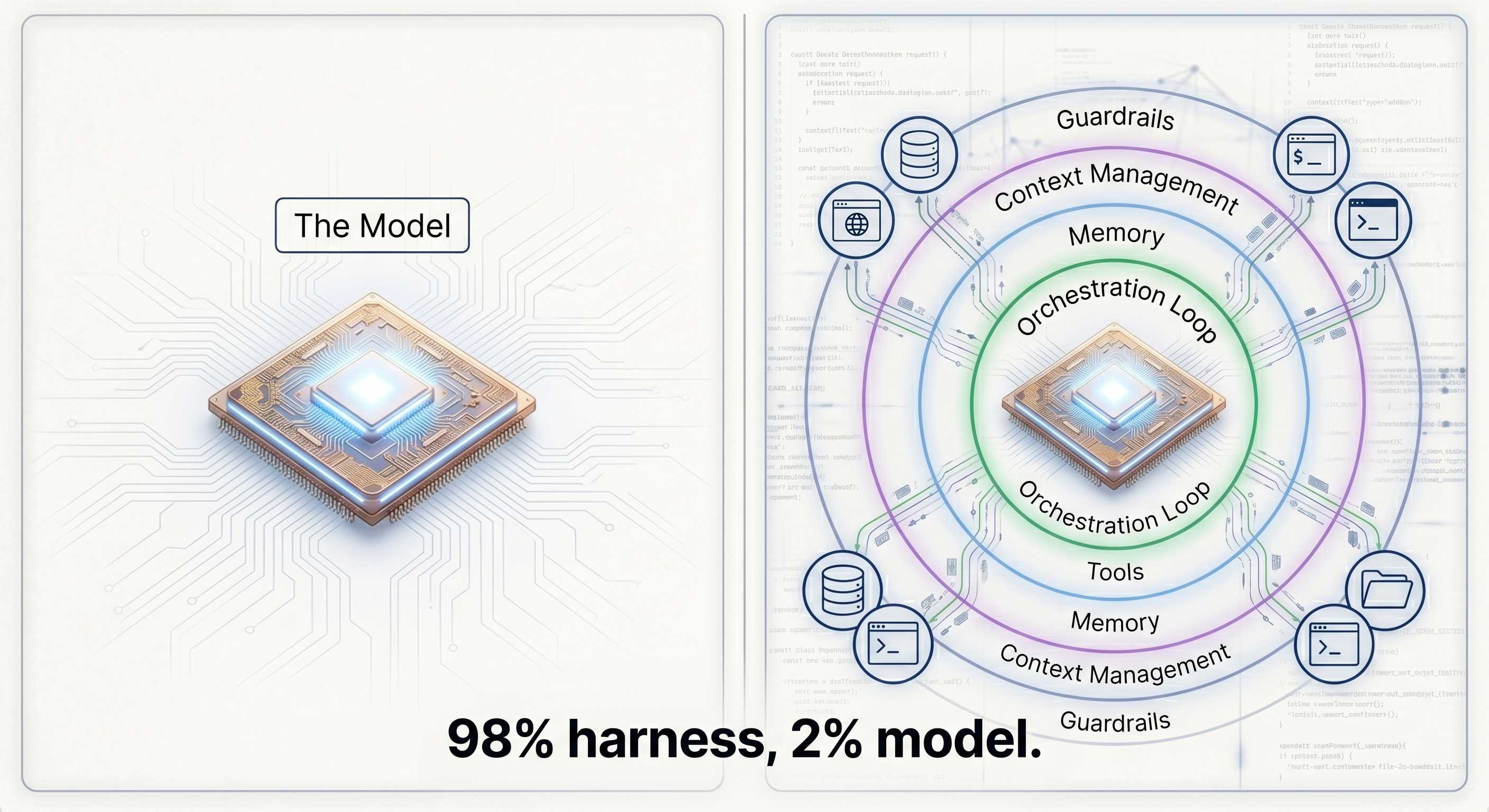
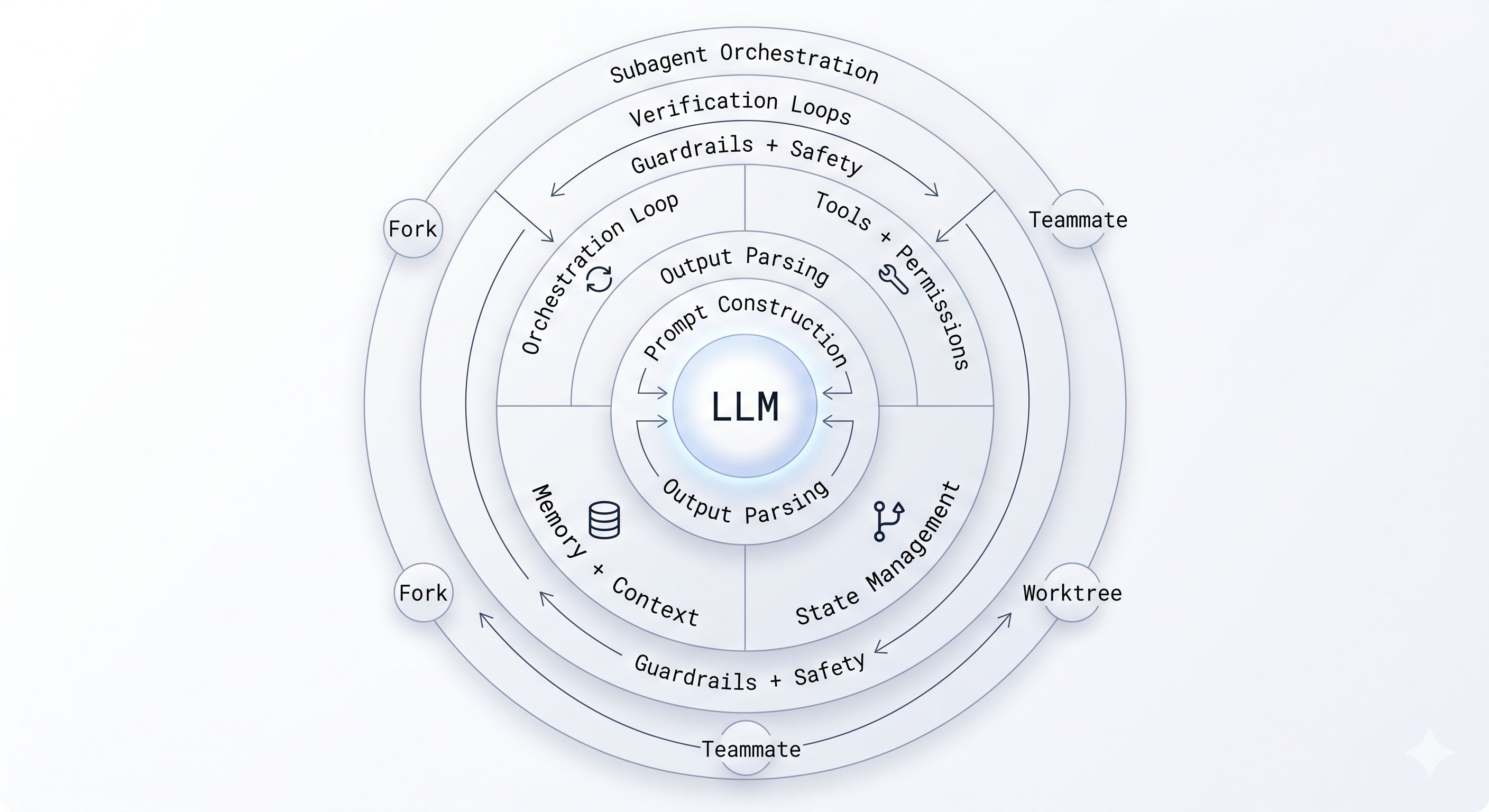
This is the central tension of building with LLMs today, and it has a name: the agent harness. The LangChain team put it cleanly: “If you’re not the model, you’re the harness.” Everything that wraps around the LLM to make it behave like an agent is the harness: the orchestration loop, the tools, the memory system, the context management, the state persistence, the error handling, the guardrails, the prompt assembly, the output parsing, the verification loops, the subagent coordination. The model is a component. The harness is the product.
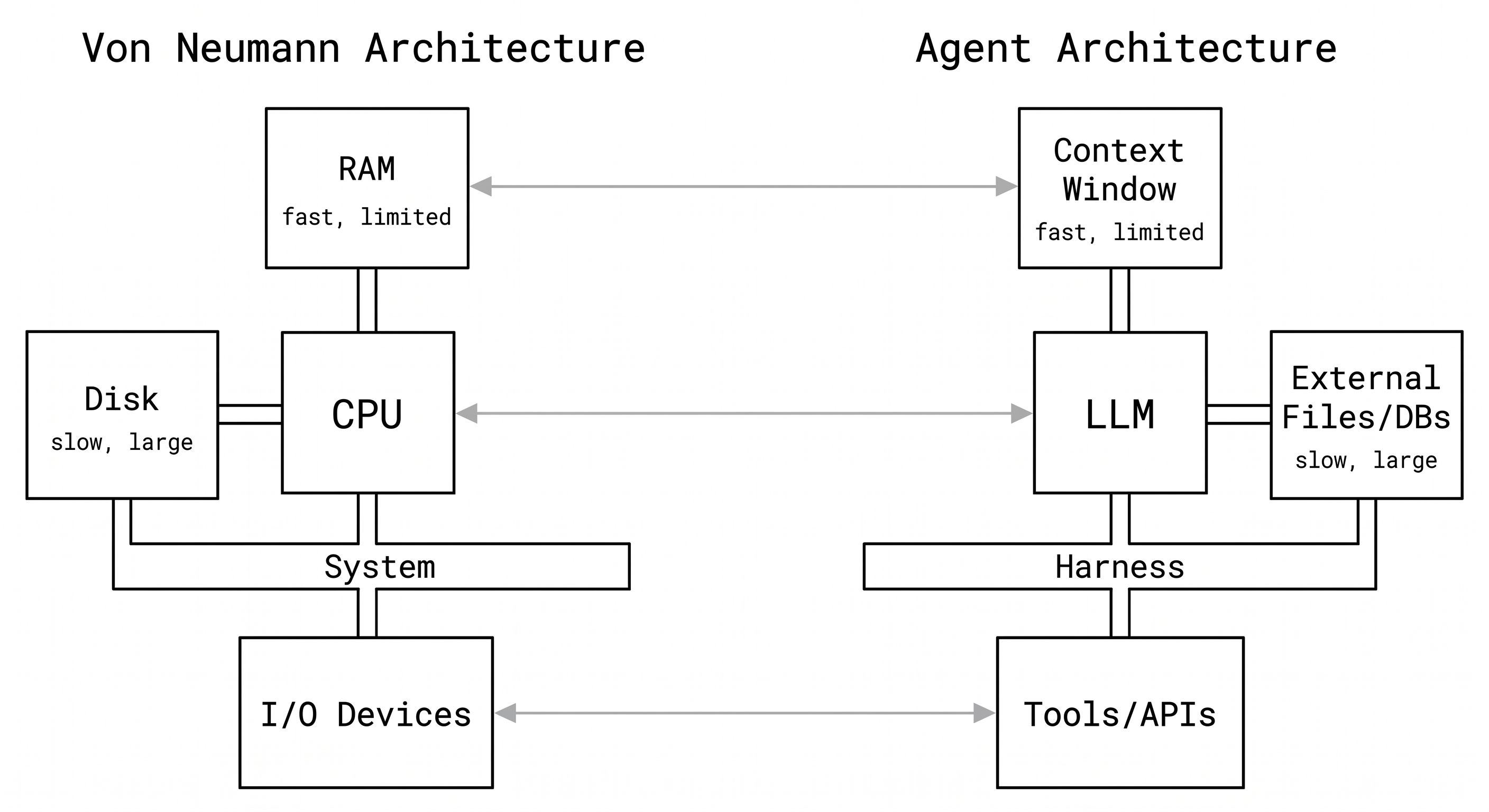
The Von Neumann Analogy
The best mental model for understanding a harness comes from computer architecture. A researcher framed it this way: a raw LLM is like a CPU with no RAM, no disk, and no I/O. Technically powerful. Practically useless on its own.
Map it out:
| Computer Component | Agent Equivalent |
|---|---|
| CPU | The LLM |
| RAM (fast, limited, expensive) | Context window |
| Disk (slow, large, cheap) | External files, databases, vector stores |
| Device drivers | Tool definitions and implementations |
| Operating system | The agent harness |
Every time you build an agent, you are reinventing the operating system. The orchestration loop is your scheduler. Context management is your memory manager. Tool execution is your I/O subsystem. Safety checks are your kernel-level permissions. These are not new problems. They are problems that OS designers solved in the 1970s and 1980s. The vocabulary has changed. The constraints are identical.
This is not a metaphor to be cute. It is a useful frame because it tells you what the hard problems actually are. Memory management in agents (what goes into the context window, when, and in what form) is as non-trivial as memory management in operating systems. Most of the bugs you will hit in production agent systems are not model bugs. They are OS bugs.
The Harness Tax
Every agent carries what I call the harness tax: the tokens the agent spends on itself before spending a single token on the user’s task. Someone benchmarked this directly across three coding agents running the same trivial task (write a Fibonacci script):
| Agent | Harness overhead per request |
|---|---|
| Pi / OpenClaw | ~2,600 input tokens |
| Codex | ~15,000 input tokens |
| Claude Code | ~27,000 input tokens |
A 40-turn session at Claude Code’s rate burns roughly 1.12 million input tokens. About half of that is harness overhead. That is real money, and it is also a real engineering constraint. Claude Code ships around 24 tool definitions on every single request. In any given session, most of those tools never get called. But each tool schema takes up tokens, and those tokens sit in the context window the whole time.
This is where it stops being just a cost problem and becomes a quality problem. Token position matters. Research from Stanford’s “Lost in the Middle” paper showed model performance degrades 30%+ when key content lands in the middle of the context window rather than at the start or end. Every token of harness overhead is a token of displacement. When your agent’s context fills up with tool schemas for tools it will never use, those tokens are physically pushing your user’s code and intent toward that degraded middle zone.
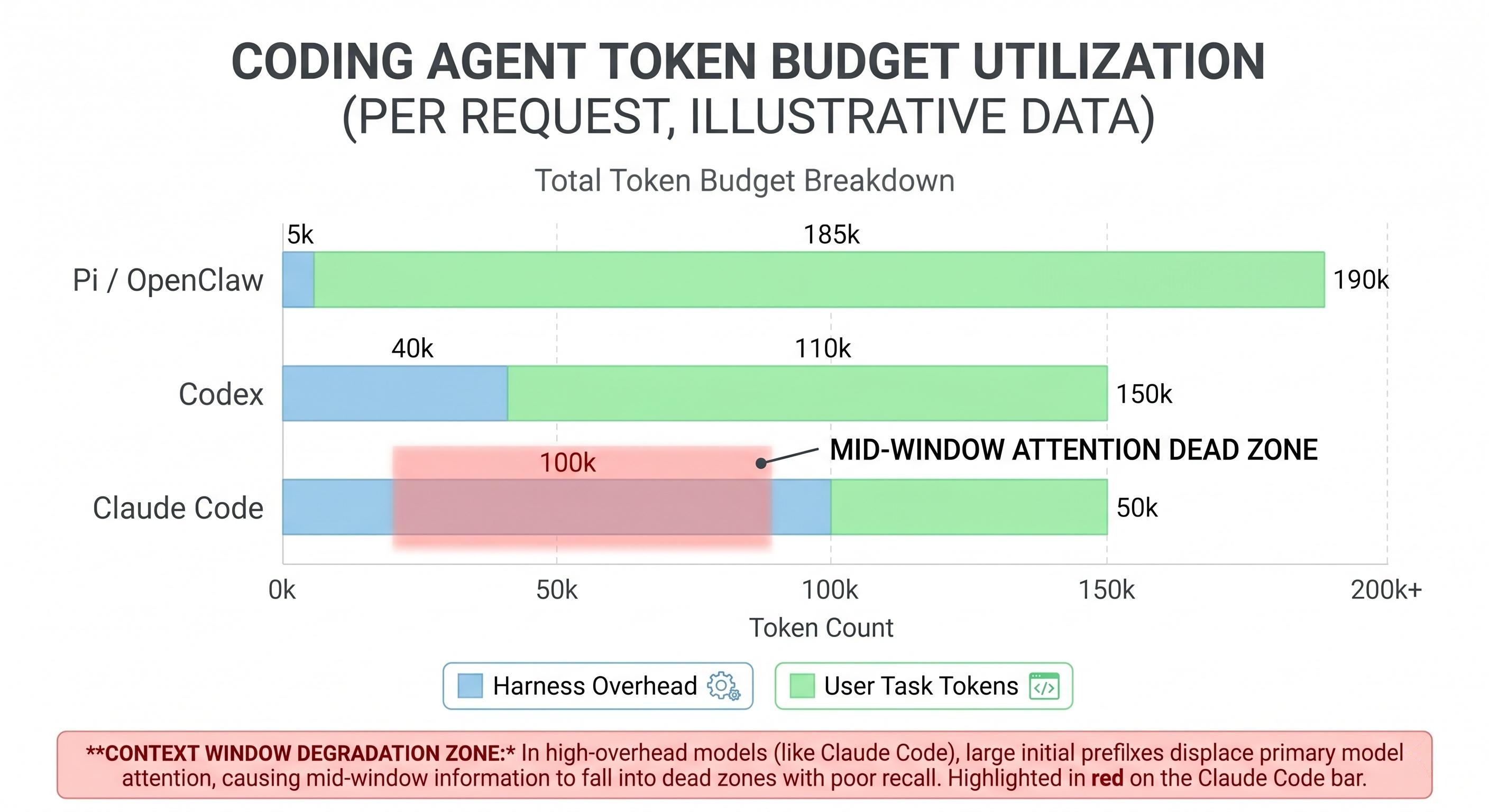
I call it context rot. The harness bloats the context, the context degrades model attention, model attention degradation hurts the quality of the actual task. A thick harness can make your agent dumber, not smarter.
The design tension is real: more harness capabilities mean more tokens, and more tokens mean worse attention distribution. Every tool you add to your agent is a tradeoff between what it can do and how well it does everything else.
Anatomy of a Production Harness
Different practitioners slice the harness differently. One breakdown lists 12 components. An open-source mini coding agent uses 6. The territory is the same either way. Here is how I group it.
The Loop: Orchestration and State
Every agent harness has an orchestration loop at its core. You may know it as ReAct (Reasoning plus Acting) or the TAO cycle (Thought, Action, Observation). The structure is always the same:
- Assemble the prompt (system instructions + tools + memory + conversation history + user message)
- Call the LLM
- Parse the output: is it a final answer, a tool call, or a handoff to another agent?
- If tool call: validate inputs, check permissions, execute in sandbox, capture output
- Package tool results as new messages
- Update context, trigger compaction if needed
- Loop back to step 1
Anthropic’s Claude Agent SDK describes their implementation as a “dumb loop where all intelligence lives in the model.” That is the right way to think about it. The loop is plumbing. It should be boring.
State management is the part that gets complicated. How does an agent resume after a context window fills? Claude Code uses git commits as checkpoints. Long-running tasks use progress files as scratchpads, and the filesystem provides continuity across context windows. LangGraph uses typed dictionaries with explicit checkpoint snapshots.
Error handling in agents is sneaky. A 10-step task with 99% per-step success has only 90.4% end-to-end success. There are four failure types worth designing for: transient failures (retry), LLM-recoverable failures (the model can self-correct), user-fixable failures (stop and ask), and unexpected failures (fail loudly and log everything). Most agent failures in production are compound failures where the root cause is two steps back.
Tools and Prompt Construction
Tools are how the agent reaches outside the context window. Each tool is a schema (name, description, input parameters, output format) injected into the prompt on every request. The harness handles registration, input validation, permission checking, sandboxed execution, and result capture.
Claude Code gates around 40 discrete tool capabilities independently. The permission model is three-staged: trust establishment (who is asking and in what context), permission check (is this action allowed for this trust level), and explicit user confirmation for high-impact operations.
Prompt construction is more nuanced than most people realize. The hierarchical assembly order matters: system prompt, tool definitions, memory files, conversation history, current user message. Changing that order changes model behavior.
The key optimization here is splitting your prompt into a stable prefix and a changing suffix. The stable prefix (system instructions, tool definitions, workspace summary) rarely changes within a session. The changing suffix (recent conversation, memory notes, current task) updates every turn. Why does this split matter? Because of prompt caching.
Anthropic’s API lets you mark cache breakpoints on content blocks using cache_control. Everything from the start of the request up to that breakpoint gets cached server-side with a 5-minute TTL. Cache reads cost roughly 10% of normal input token pricing. Cache writes (the first time) cost 25% more. After that first call, every subsequent turn within the TTL window gets the prefix at a 90% discount.
Here is how an open-source coding agent (mini-coding-agent) structures this in practice:
def build_prefix(workspace_context):
"""Stable portion of the prompt. Cached across turns."""
return {
"role": "system",
"content": [
{"type": "text", "text": AGENT_INSTRUCTIONS},
{"type": "text", "text": workspace_context.summary()},
{"type": "text", "text": tool_descriptions(),
"cache_control": {"type": "ephemeral"}} # <-- cache breakpoint
]
}
def build_prompt(prefix, memory_notes, history, user_message):
"""Combines cached prefix with per-turn changing suffix."""
return [prefix] + memory_notes + history + [
{"role": "user", "content": user_message}
]
The build_prefix function assembles the agent instructions, a workspace summary (git branch, repo root, project docs), and tool descriptions into a single block with a cache breakpoint at the end. Everything after that breakpoint (memory, transcript, user message) is the changing suffix that gets processed at full price each turn.
Claude Code follows the same principle but at a much larger scale. Its stable prefix runs about 27,000 tokens (system prompt + 24-40 tool schemas + memory index files). The math on caching that prefix is significant:
Without caching: 40-turn session x 27k prefix = 1,080,000 prefix tokens at full price
With caching: first turn pays 1.25x write cost on 27k tokens, remaining 39 turns pay 0.1x read cost
Result: roughly 87% savings on the stable prefix portion alone
The 5-minute TTL resets on each cache hit, so as long as the agent makes at least one API call every few minutes (which is typical in interactive coding sessions), the cache stays warm. The tradeoff is architectural: anything you put in the prefix must be truly stable. If you change even one token in the cached block, the entire cache invalidates and you pay the full write cost again. This is one reason Claude Code loads memory files in a specific order and keeps tool definitions static across turns.
Output parsing is where most brittle failures live. With native tool calling (structured tool_calls objects), you bypass a lot of free-text parsing pain. Before tool use was standardized, agents had to parse structured output out of prose, and models would use slightly different formats, omit fields, or add extra text. The lesson from Claude Code’s build of the AskUserQuestion tool: even a well-designed tool fails if the model does not understand when to call it. Tool design is as much about the model’s training distribution as it is about the schema.
Memory and Context
Memory in agents has two layers.
Short-term memory is the conversation history in the context window. It is fast and immediately available. It is also expensive and finite.
Long-term memory is everything that persists beyond a single context window. This includes project-level knowledge files (CLAUDE.md, AGENTS.md), session transcripts, task histories, user preferences. Claude Code uses a three-tier approach: a lightweight index file (150 characters max per entry, always loaded), detailed topic files loaded on demand, and raw transcripts used only for search.
The LangChain team makes a point worth sitting with: memory is not a module you plug into an agent harness. The team at Letta put it this way: “Asking to plug memory into an agent harness is like asking to plug driving into a car.” The harness controls what gets loaded into context, what survives compaction, how the filesystem is exposed, and how metadata is presented. Memory and harness are deeply coupled. You cannot really separate them.
The implication is uncomfortable: if your memory lives inside a closed harness (OpenAI’s Responses API with server-side compaction, Anthropic’s Managed Agents), you do not own your agent’s accumulated knowledge. Switching models means losing threads. This is not an accident. Model providers have strong incentives to lock users in via memory, because model switching costs are near zero today, but agent switching costs (accumulated state, learned preferences, project context) are high.
Context management is the harness’s most active responsibility during a long task:
- Compaction: when context fills, summarize old turns into a dense representation and drop the originals
- Observation masking: verbose tool outputs (like a full file listing) get hidden from the active window after their immediate turn
- Just-in-time retrieval: instead of loading all memory files at startup, load only what is relevant to the current task
- Subagent delegation: offload context-heavy subtasks to subagents that run in their own context windows and return only 1,000-2,000 token summaries
The right approach is to keep recent events rich while compressing older events aggressively. Recent context is almost always more relevant. Old context can usually be summarized or dropped.
Guardrails and Verification
Verification loops are the highest-ROI investment in a production harness. The Claude Code team measured a 2-3x quality improvement from adding verification. There are three levels:
- Rules-based: run tests, linters, type checkers after each change. Fast and deterministic.
- Visual: take a screenshot and confirm the UI looks correct. Works for frontend work where tests do not tell the full story.
- LLM-as-judge: have a separate model review the output for correctness, completeness, or policy compliance. Expensive but catches things rules miss.
Subagent orchestration lets a harness parallelize work across multiple agent instances. Claude Code supports three patterns:
- Fork: a byte-identical copy of the current agent context, for truly parallel independent tasks
- Teammate: a separate agent in its own terminal pane with a file-based mailbox for coordination
- Worktree: an agent with its own git worktree and isolated branch, for tasks that need to diverge from the main codebase without interference
Thin Harness, Fat Skills
Here is a principle that surprised me when I first encountered it: giving your agent fewer tools often makes it better.
Pi (the reasoning engine behind OpenClaw) uses exactly four tools: read file, write file, edit file, and shell command. That is it. The reasoning is straightforward. Models trained on millions of GitHub repos and shell sessions already know how to use grep, find, ls, git log, and a thousand other utilities. If you want to search files, you do not need a search_files tool. You can just run grep -r. The tool schema would consume tokens to define something the model can already do with a shell command. Thin harness, fat skills.
The evidence from model evolution makes this trend concrete. Community benchmarks tracked harness changes across three Claude model generations:
- Sonnet 4.5: the harness needed explicit context reset mechanisms. When the model sensed it was running out of context, the harness would trigger a structured wrap-up and restart.
- Opus 4.5: the model handled context pressure better on its own. The explicit reset logic became unnecessary. It got removed.
- Opus 4.6: the harness had been doing sprint decomposition, breaking large tasks into smaller subtasks with explicit planning steps. With Opus 4.6, removing that entirely improved performance. The model planned better without the scaffolding.
Three model generations. Three layers of harness removed. What was load-bearing infrastructure in January was dead weight by March.
Manus (another coding agent) rebuilt their entire harness five times in six months. Each rebuild removed complexity. The team at Vercel reportedly removed 80% of the tools from v0 and got better results. Claude Code achieves 95% context reduction in some configurations via lazy loading: tools and context loaded only when needed, not upfront.
The pattern is consistent: as models improve, the complexity that compensates for their limitations becomes unnecessary. Harness code is temporary by nature. If you are writing harness logic that feels permanent, you are probably compensating for a model limitation that will be trained away within a generation or two.
There is a real tension here though. The “thin harness” principle applies to general-purpose capabilities. Task-specific harnesses tell a different story. One practitioner reported a +16 percentage point improvement by replacing a generic agent setup with a harness engineered specifically for financial data tasks. Generic harnesses give you acceptable performance across many tasks. Task-specific harnesses give you significantly better performance on the tasks that matter. Models are also “non-fungible in their harness”: dropping Codex into the Claude Code harness produces poor results because models are post-trained with specific harness assumptions baked in. The harness and the model form a unit.
The Meta-Harness
The most interesting recent development in this space is work coming out of Stanford: automated harness optimization.
The setup is a five-step loop:
- Inspect: an LLM agent searches the filesystem for previous task results and execution traces
- Diagnose: it reasons about what failure modes the traces reveal
- Propose: it writes new harness code, typically a single-file Python change
- Evaluate: run the modified harness on a task distribution, record the reward
- Update: push results back to the filesystem, loop
They used Claude Code as the proposer agent. After enough iterations of this loop, the automated system hit 76.4% pass rate on TerminalBench, surpassing hand-designed harnesses. The key finding: the system needs unrestricted access to all previous experiment history. Text optimization loops that only see reward scores and summaries underperform badly. The dependencies are long-horizon. You need the full trace to diagnose the root cause.
This connects to a concept researchers describe as the model-harness training loop: what the harness does today gets trained into the model tomorrow. Anthropic observes which harness primitives are most effective in production, and subsequent model versions are post-trained to be better at using them natively. Then the harness can shed that layer and push to the next frontier. The harness is, in a real sense, the model’s training data pipeline for the next generation.
The business dimension matters too. Agent framework developers have pointed out that model providers are strongly incentivized to build lock-in at the harness layer, specifically through memory. OpenAI generates encrypted compaction summaries that cannot be used outside their ecosystem. Anthropic’s Claude Managed Agents puts the entire agent runtime behind an API. Switching the underlying model is nearly free today. Switching the harness, with all the accumulated memory and learned preferences it holds, is not.
If you do not own your harness, you do not own your agent.
Closing Thoughts
The thing I keep coming back to is how much engineering surface area lives outside the model. When an agent fails in production, the first instinct is to blame the LLM. Usually the problem is elsewhere: a tool schema that ambiguously describes when a tool should be called, a compaction strategy that lost a key piece of project context, a verification loop that was never implemented, an error type that was not classified and got silently swallowed.
A few principles that have crystallized for me after going deep on this:
Measure your harness tax first. Before optimizing anything else, count the tokens your agent spends before the user’s task begins. You may be surprised. Many teams have never looked at this number.
Build for removal. Every piece of harness logic should have a mental annotation: “this becomes unnecessary when the model can do X natively.” When that model generation ships, delete the code. Treat harness complexity as technical debt with a known expiration date.
Invest in verification loops. The data is consistent: 2-3x quality improvement from good verification, for relatively low implementation cost. Rules-based verification (linters, tests, type checkers) is the easiest starting point and often sufficient for 80% of the quality gain.
Be deliberate about memory architecture. Memory is the stickiest part of the stack. The decisions you make about where memory lives and in what format determine what vendor you are locked into and how much of your agent’s accumulated knowledge you actually own. Design this intentionally, not by accident.
The harness is where most of the interesting engineering in agentic AI lives right now. The model is improving fast. The harness is where the real systems thinking happens. And as the LangChain team put it: if you’re not the model, you’re the harness.
]]>